EnergyLabでベースラインモデルを作成するには2つの方法があります:
- 自動ベースライン
- カスタムベースライン
1. 自動ベースラインの作成
これは消費データと影響力のあるパラメータに基づいて、基準状況をモデル化する最も迅速で効果的な方法です。
必要なのは次のことだけである:
- 基準期間の選択、
- ターゲット変数、
- 潜在的な影響力のあるパラメータ
- モデルの頻度(毎時、毎日など)。
データソースエリアから、「Add」をクリックし、次に「Simplified model 」をクリックする。
以下のビデオでは、様々な段階を説明している:
その後、データ・ソースで自動ベースラインを見つけ、他のシリーズと同様にウィジェットで使用することができます。
上のビデオで作成したテンプレートを使った例:

2. カスタムベースラインの作成
カスタムベースラインは、参照状況を定義しモデル化する最も正確で適応性のある方法です。基準期間と影響因子を最適に定義するために、データを探索することができます。
モデルの作成
EnergyLab ワークスペースに移動し、画面上部の「Create a model + 」 をクリックします:
ワークフローに名前を付け、必要な情報を入力し、適用を クリックします:
- タイトル(一意でなければならない)。
- リンクするプロジェクト(プロジェクトを追加するには 「+」をクリックしてください。)
- タグ(「+」をクリックしてタグを追加する)
- ワークフロー・タイプ:現在のところ、「Empty 」タイプのみ利用可能です。

ワークフローはいくつでも作成できますが、プラットフォーム上に配置できるのは100個までです。それ以上のワークフローをデプロイする必要がある場合は、METRONのオペレーションエンジニアにご連絡ください。
モデル作成には5つのステップがあります:
- A) データ復元
- B) データ構築
- C) データクレンジング
- D) モデリング
- E) デプロイメント
5つの各段階で、使用されたデータを見ることができる。

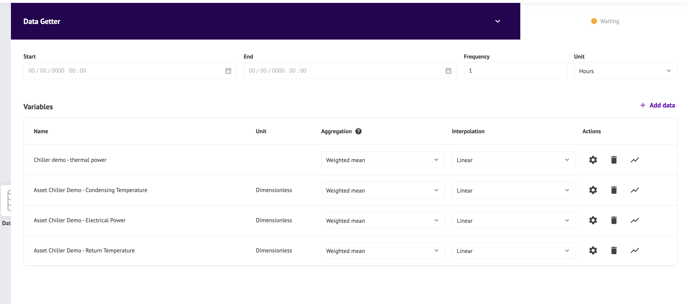
A) データ回収
このステップでは、METRONプラットフォーム上のデータソースから 分析に関連するデータを取得します。
手順:
- 取得したい データの開始日時と終了日時を選択します。
- ポイント 収集の頻度を 選択します(粒度とも呼ばれます)。
- データを取得したい 異なるシリーズを 選択します。
- 各変数について、集計と補間を選択します。
変数の数、粒度、抽出したい時間間隔によっては、この操作に時間がかかることがあります。
B) データ・クレンジング
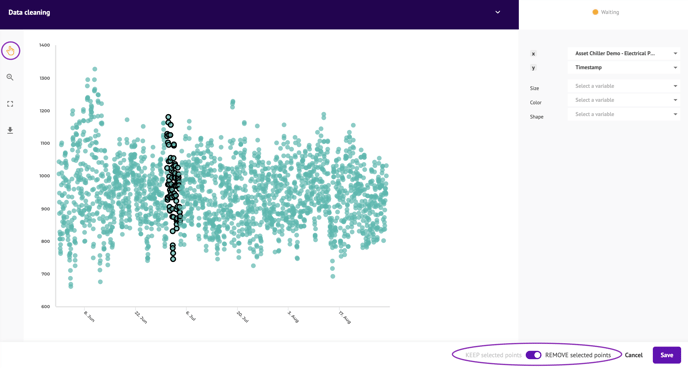
このブロックでは、外れ値(すなわち、誤った測定値や、メンテナンスやインシデントなどの孤立したイベントを表すポイント)を除去することによって、データをクリーンアップすることができます。
これを行うには、物理的制約(エネルギー>0など)を実装するルールを作成します。また、ポイントのクラウドから、維持または削除したいポイントをグラフィカルに選択することもできます。
操作方法:
データクレンジング方法を選択します:

- ルール付き:
- 変数、演算子、2番目のオペランド(値または変数)を選択します。
- 点群から グラフ選択を使用する:
- X/Y軸の異なる変数を選択します。
- 必要であれば、色、形、サイズのための他の変数を追加します。
- 選択ツールを使って、維持または削除したい点を選択します。
- グラフの複数の領域を選択するには、SHIFTキーを押しながら、維持または削除したい異なる領域をクリックする。
- 選択したポイントを維持するか削除するかは、右下隅で選択できます。
- 自動クリーニング:
- アルゴリズムにデータをクリーンアップさせます。
このブロックで削除したポイントはEnergyLabエリアでのみ削除されますが、データはData Visualisationエリアでは表示されます。この段階はモデルを構築するために使用され、定義された参照状況のみを学習します。
C) データ構築
このブロックでは、既存の変数を組み合わせて新しい変数を作成することにより、最初のステップで選択したデータセットを充実させることができます。
手順
左側では、計算に使用したい変数をインポートして、名前をつけることができます。
右側では、それぞれの計算結果に名前を付けることができます。
計算パネルを使って、新しい変数の計算式を定義します:
- 算術演算子 +, -, *, /, ** (power), % (modulo), // (floor division)。
- 比較演算子 <, >, <=, >=,!=, ==。
- ブール演算子|(または)、&(および)、〜(ない)
- 数学関数 sin、cos、exp、log、expm1(expマイナス1)、log1p(log(1+x))、sqrt、sinh、cosh、tanh、arcsin、arccos、arctan、arccosh、arcsinh、arctanh、abs、arctan2
例:エネルギーの指数+生産の対数を作成したい場合は、「exp(energy) + log(production) 」を使用する。
消費量が10より大きく、生産量が2000より小さい場合のブール値は、「消費量 > 10 & 生産量 < 2000 」となる。

計算が正しいことを確実にするために、変数の単位に注意してください!
D) モデリング
このブロックでは、トレーニングしたいモデルを選択できます。
インストラクション:
- モデルの選択: 1つ、2つ、または3つすべてのモデルを選択して、それらを比較し、どれが最も適しているかを定義し、結果をプレビューすることができます。
- 線形回帰: このモデルがデフォルトで選択されます。
- ランダム・フォレスト: 非線形現象をモデルする。
- kNN: 類似ポイントとの直接比較のため。
- 予測するターゲット変数を選択する:
- 例:ESCU の電力消費。
- 予測に使用したい特性変数を選択する
- 例: このSEUについて識別された影響力のある要因。
- トレーニング・データとテスト・データを分離する方法を選択します:
- 比率: データの最初のX%をトレーニングに使用し、残りをテストに使用する。
- 日付/時刻:日付/時刻の前のデータをトレーニングに使用し、その次のデータをテストに使用する。
- 例:2023年をトレーニング期間とし、2024年をテスト期間とすることができる。
- モデルの計算を開始し、そのパフォーマンスを比較することができる。
もっと詳しく知りたい方は、モデルの結果を解釈する (近日公開)の記事をお読みください。
E) 配置
このブロックでは、モデルを保存し、プラットフォーム上に公開します。これは、Data sourcesで見つけることができます。モデルが公開されると、入力データが利用可能である限り、予測はライブで計算されます。
手順は以下の通りです:
- 前のブロックでトレーニングしたモデルの中からモデルを選択します。
- モデルの名前を入力します。
- 履歴を計算する日付を選択します。
注意: デプロイメントには、トレーニングでフィルタリングされた外れ値を含む、すべてのデータに対する予測が含まれます。