Il existe 2 manières de créer des modèles de référence avec EnergyLab:
- La baseline automatique
- La baseline personnalisée.
1. Créer une baseline automatique
Il s'agit du moyen le plus rapide et le plus efficace de modéliser une situation de référence, à partir d’une donnée de consommation et de paramètre influents.
Il requiert simplement :
- Le choix d'une période de référence,
- La variable cible,
- Les paramètres influents potentiels.
- La fréquence du modèle (horaire, journalière...)
Depuis l'espace Sources de données, cliquez sur "Ajouter" puis "Modèle simplifié"
La vidéo ci-dessous reprend les différentes étapes:
Vous pourrez ensuite retrouver votre baseline automatique dans les Sources de données et l'utiliser dans un widget comme toute autre série.
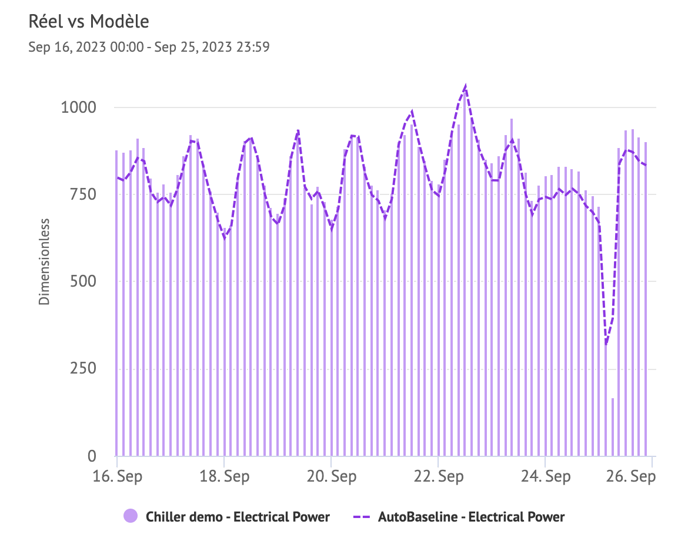
Exemple avec le modèle créé à partir de la vidéo ci-dessus :
2. Créer une baseline personnalisée
La baseline personnalisée est le moyen le plus précis et adaptable de définir et modéliser une situation de référence. Il permet d’explorer les données afin de définir au mieux la période de référence et les facteurs influents.
Créer un modèle
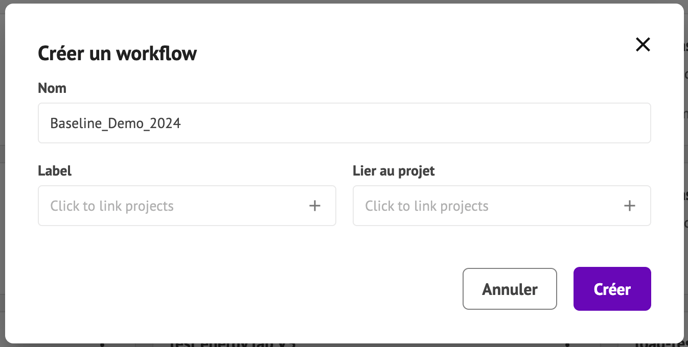
Rendez-vous dans l'espace de travail EnergyLab puis cliquez sur "Créer un modèle + " en haut de votre écran:

- Titre (doit être unique).
- Projet à lier (cliquez sur "+" pour ajouter des projets)
- Tags (cliquez sur "+" pour ajouter des tags)
- Type de workflow : pour le moment, seul le type "Vide" est disponible.
Veuillez noter que vous pouvez créer autant de workflows que vous le souhaitez mais que vous ne pouvez en déployer que 100 sur la plateforme. Si vous avez besoin de déployer plus de workflows, veuillez contacter votre ingénieur opérations METRON.
La création de modèle se déroule en 5 étapes :
- A) Récupération des données
- B) Construction des données
- C) Nettoyage des données
- D) Modélisation
- E) Déploiement
A chacune des 5 étapes, vous pouvez visualiser les données utilisées. (ajouter oeil)

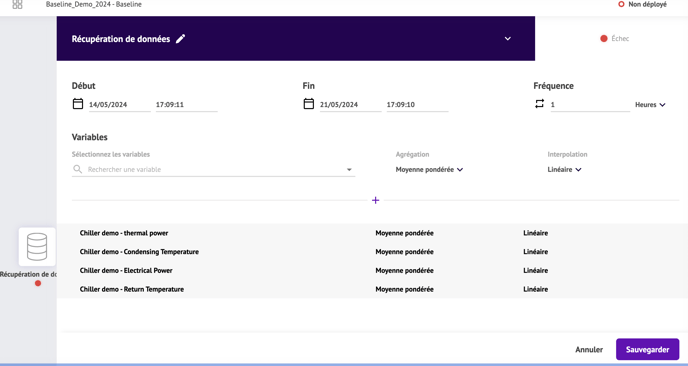
A) Récupération de données
À cette étape, vous allez rechercher les données pertinentes pour effectuer votre analyse, parmi les sources de données de votre plateforme METRON.
Instructions :
- Sélectionnez la date et l'heure de début et de fin des données que vous souhaitez extraire.
- Sélectionnez la fréquence de votre collecte de points (également appelée granularité)
- Sélectionnez les différentes séries dont vous souhaitez récupérer les données.
- Pour chaque variable : sélectionnez l'agrégation et l'interpolation.
En fonction du nombre de variables, de la granularité et de l'intervalle de temps que vous souhaitez extraire, cette opération peut prendre un certain temps.
B) Nettoyage de données
Dans ce bloc, vous pouvez nettoyer vos données en supprimant les valeurs aberrantes (.i.e. les points représentant des mesures erronées ou des événement isolés de type maintenance ou incident).
Pour ce faire, vous pouvez créer des règles pour implémenter des contraintes physiques (ex: énergie >0). Vous pouvez aussi sélectionner graphiquement dans un nuage de points ceux que vous souhaitez conserver ou retirer.
Instructions :
Choisissez une méthode de nettoyage de données:
- Avec des règles :
- Sélectionnez une variable, un opérateur et un second opérande (valeur ou variable).
- A partir d'un nuage de points: Utiliser la sélection graphique :
- Sélectionner les différentes variables pour les axes X/Y
- Ajouter éventuellement d'autres variables pour la couleur, la forme et la taille.
- Sélectionnez les points que vous souhaitez conserver ou supprimer avec l'outil de sélection.
- Pour sélectionner plusieurs zones du graphique, maintenez la touche MAJ et cliquez sur les différentes zones que vous souhaitez conserver ou supprimer.
- Vous pouvez choisir de conserver ou supprimer les points sélectionnés en bas à droite.

- Nettoyage automatique:
- Laissez notre algorithme nettoyer pour vous la donnée.
Notez que les points que vous aurez supprimés dans ce bloc ne le seront que dans l'espace EnergyLab, ces données seront toujours visible dans l'espace Visualisation de données. Cette étape sert à la construction du modèle, pour qu'il n'apprenne que sur la situation de référence définie.
C) Construction de données
Dans ce bloc, vous pouvez enrichir votre jeu de données sélectionné à la première étape, en combinant des variables existantes pour en créer de nouvelles.
Instructions :
Sur la gauche, vous pouvez importer et nommer les variables que vous voulez utiliser dans votre calcul.
Sur la droite, vous pouvez nommer le résultat de chaque calcul.
Utilisez le panneau de calcul pour définir la formule de votre nouvelle variable (voir ci-dessous), comprenant :
- Les opérateurs arithmétiques +, -, *, /, ** (puissance), % (modulo), // (division plancher).
- Les opérateurs de comparaison <, >, <=, >=,!=, ==
- Opérateurs booléens | (ou), & (et), et ~ (pas)
- Les fonctions mathématiques sin, cos, exp, log, expm1 (exp moins un), log1p (log(1+x)), sqrt, sinh, cosh, tanh, arcsin, arccos, arctan, arccosh, arcsinh, arctanh, abs et arctan2
Exemple : Si vous voulez créer l'exponentielle de l'énergie + le log de la production, vous utiliserez "exp(énergie) + log(production)".
Un booléen d'une consommation supérieure à 10 et d'une production inférieure à 2000 serait "consommation > 10 & production < 2000".

Pour que votre calcul soit juste, faites bien attention aux unités de vos variables !
Modélisation
Dans ce bloc, vous pouvez sélectionner le ou les modèle(s) que vous souhaitez entraîner.
Instruction :
- Choix du ou des modèle(s) : vous pouvez choisir 1, 2 ou les 3 modèles afin de les comparer et définir lequel sera le plus adapté et prévisualiser les résultats.
- Régression linéaire : ce modèle est sélectionné par défaut.
- Random forest : pour modéliser les phénomènes non linéaires.
- kNN: pour se comparer directement à des points similaires.
- Sélectionnez la variable cible à prédire:
- Ex: la consommation électrique d'un UES.
- Sélectionnez les variables caractéristiques que vous souhaitez utiliser pour votre prédiction
- Ex: les facteurs influents identifiés pour cet UES.
- Sélectionnez votre méthode de séparation des données d'entrainement et de test :
- Ratio : Les premiers X% des données seront utilisés pour l'entraînement, le reste pour les tests.
-
- Date/heure : Les données précédant la date/heure seront utilisées pour l'entrainement et celles qui suivent seront utilisées pour les tests.
- Ex: On peut utiliser l'année 2023 comme période d'entrainement et les données 2024 pour les tests.
- Lancer le calcul des modèles, vous pourrez ensuite comparer leur performance.
Pour en savoir plus, consultez l'article Interpreter les résultats d’un modèle (à venir).
Déploiement
Dans ce bloc, vous allez enregistrer votre modèle et le publier sur la plateforme. Vous pourrez le retrouver dans Sources de données. Une fois un modèle publié, les prédictions seront calculées en direct tant que les données d'entrée seront disponibles.
Instruction :
- Choisir un modèle parmi ceux qui ont été entrainés dans le bloc précédent.
- Entrez un nom pour votre modèle.
- Sélectionner une date à partir de laquelle calculer l'historique.
Note: Le déploiement inclut des prédictions sur toutes les données, y compris les valeurs aberrantes qui ont été filtrées dans l'entrainement.